Data Warehouse w/SSIS
Download this Project @ GitHub
Posted on August 15, 2020
Data Modeling
ERDPlus is a free website with an easy to use GUI for building Entity Relationship Diagrams (ERD). Proper data modeling is a keystone for a long sustaining database. Normalization is commonly used to reduce data redundancy and improve write operations. The third normal form (3NF) is commonly used and is best characterized as "[every] non-key [attribute] must provide a fact about the key, the whole key, and nothing but the key", as quoted by Bill Kent. The Operational data for Area of Responsibility used in this example below follows the 3NF pattern:
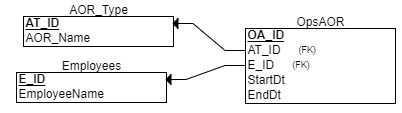
Data Warehouse
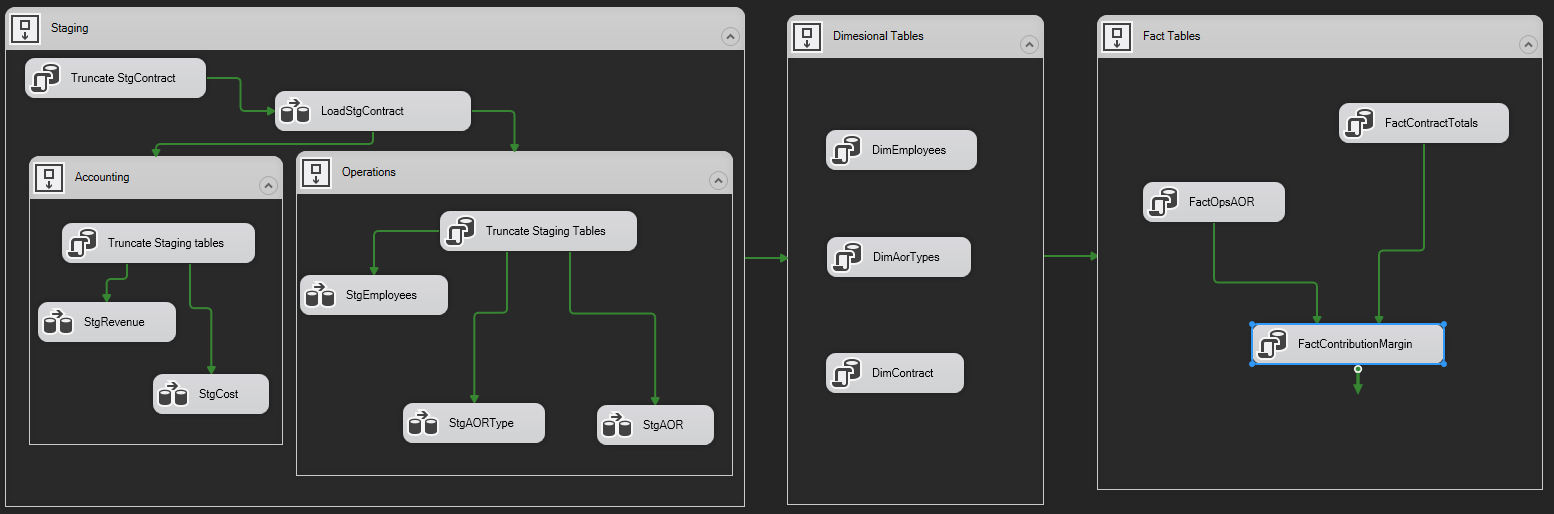
Often businesses will find themselves running different systems for Finance and Operations. A data warehouse is able to become the one source of truth by combining those systems together. Staging tables match the data 1-to-1 from the system it is replicating. This allows the reporting analysis to be done on the Data Warehouse server. Segragating this work frees the load from the Production servers running the transactional systems. Here is a diagram of the process:

An important concept to note is compartmentalizing processes. Free up analytical processing from the Transactional systems by having the Data Warehouse on its own server. Build security at each step along the way. Audit the data for privacy and security; an example being that SSN should not be identifiable to the average user in the Data Warehouse. Randomize or encrypt data tying to a specfic person. Aggregate Fact tables to obscure specifics that could identify individuals.
Contribution Margin Report
A Contribution Margin report gives important insight into how well a company can cover variable costs with revenue by calculating total earnings. The Financial data has been over-simplified to tie Revenue and Cost back to a Contract. The Data Warehouse is designed following the Snowflake Schema with Dimensional tables surrounding denormalized Fact tables, following the Kimball architecture model. The Contracts are used to tie both systems together and gives the business a more complete picture. Denormalizing the tables allows for faster report building and is more friendly for Analyst query builders. Here is a bare bones ERD of this example's Data Warehouse:
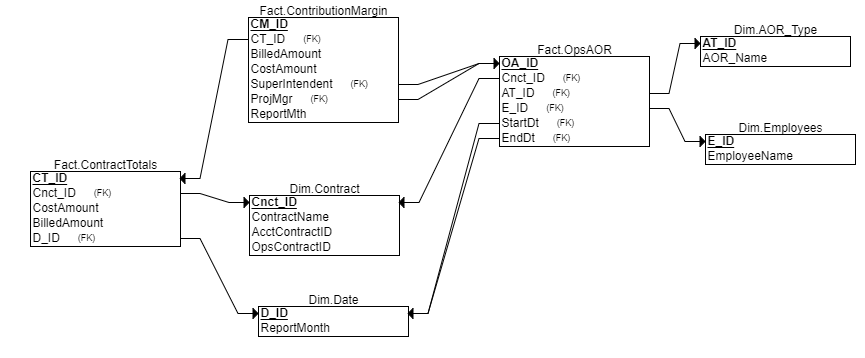
With the databases designed and implemented, SQL Server Integration Services (SSIS) is used to tie the systems together and build the reporting tables. SSIS Extracts the data from the source server's database, Transforms the data to match the destination server, and Loads the data to the destination database (ETL). The package can be broken into three parts:
- Load the Staging tables matching the source 1-to-1
- Build the Dimension tables
- Build the Fact tables
Merge Statement
A MERGE statement is used to load and update the data for the Dimensionalized tables. This takes the data from a source and to modify a target. The source could be another table or a query of the values needed for the target table. The matching columns are defined in the ON definition, from there three cases can occur:
- MATCHED
- - A row from the target and source equal each other from the ON definition
- - Usually update data in the target from the source
- NOT MATCHED
- - A row from the source does not match a row from the target
- - Usually insert data from the source into the target
- NOT MATCHED BY SOURCE
- - A row from the target does not have a match from the source
- - Usually delete the row from the target that does not have a matching row in the source
MERGE [Dim].[Employees] AS TARGET
USING [Stg].[Employees] AS SOURCE
ON (TARGET.[E_ID] = SOURCE.[E_ID])
WHEN MATCHED AND TARGET.[EmployeeName] <> SOURCE.[EmployeeName]
THEN UPDATE SET
TARGET.[EmployeeName] = SOURCE.[EmployeeName]
WHEN NOT MATCHED BY TARGET
THEN INSERT ([E_ID], [EmployeeName])
VALUES (SOURCE.[E_ID], SOURCE.[EmployeeName])
WHEN NOT MATCHED BY SOURCE
THEN DELETE
OUTPUT $action,
DELETED.DE_ID AS TargetDE_ID,
DELETED.[E_ID] AS TargetE_ID,
DELETED.EmployeeName AS TargetEmployeeName,
INSERTED.DE_ID AS SourceDE_ID,
INSERTED.E_ID AS SourceE_ID,
INSERTED.EmployeeName AS SourceEmployeeName;
Slowly Changing Dimensions
This can be taken a step further and modified to implement Slowly Changing Dimensions; this answers how to handle data as it changes over time. Slowly changing dimensions could be used to re-create a report at any given time for the system by tracking the changes of a Dimension's values. There are seven different types and they are:
- Type 0 = Fixed Dimension
- - No changes, dimensions never change after creation
- Type 1 = No History
- - Update record directly for current state, no history
- Type 2 = Row Versioning
- - Track changes with a current flag, active date, and other metadata
- Type 3 = Previous Value
- - Track changes for a specific attribute, add a column to show the previous value which is updated as further changes occur
- Type 4 = History Table
- - Show current value in dimension table but track all changes in separate table
- Type 5 = Hybrid
- - Utilize techniques from Type 1 and 4 to track changes
- Type 6 = Hybrid
- - Utilize techniques from Type 1, 2 and 3 to track changes
- Type 7 = Hybrid
- - Utilize techniques from Type 1 and 2 to track changes
Deployment
Deploy the package from within Visual Studio through the Project -> Deploy option and follow the guided wizard:
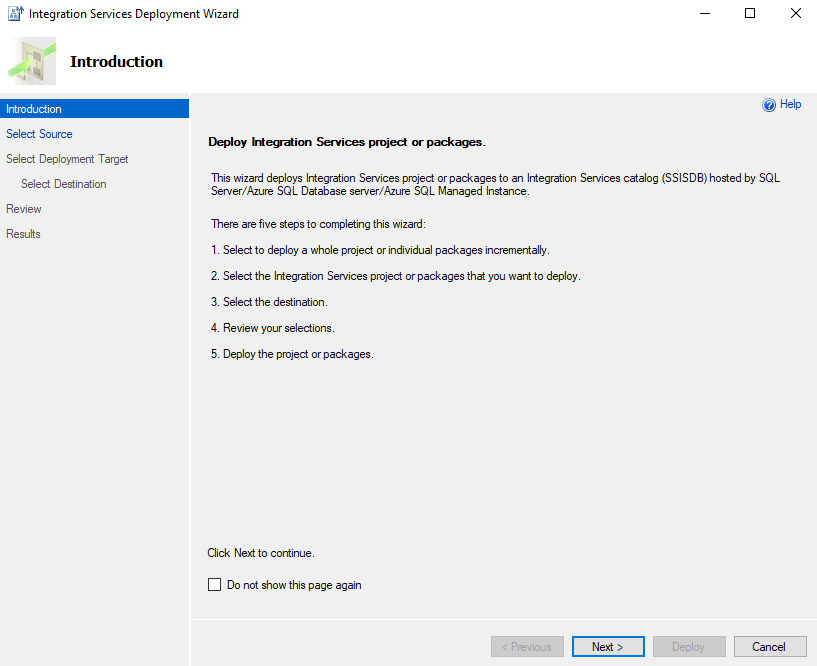
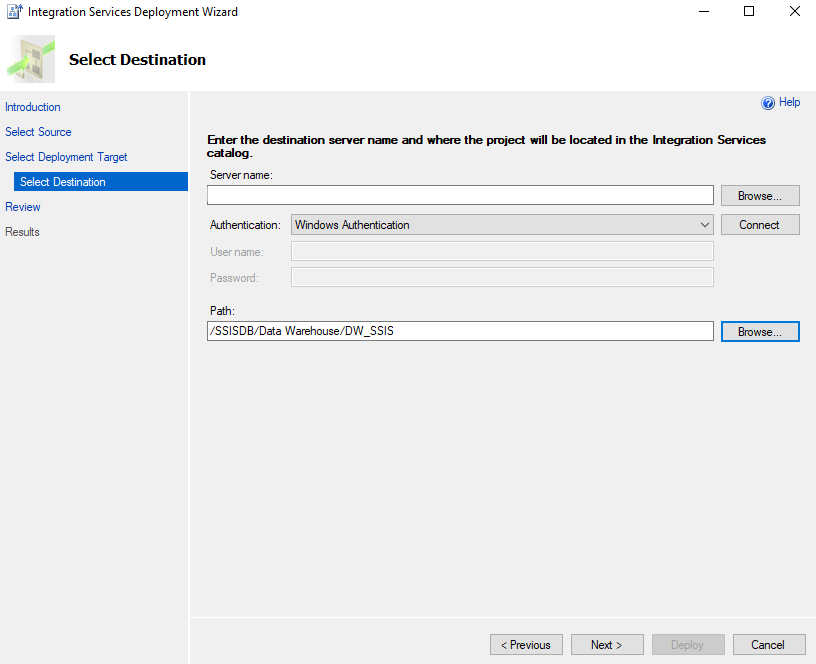
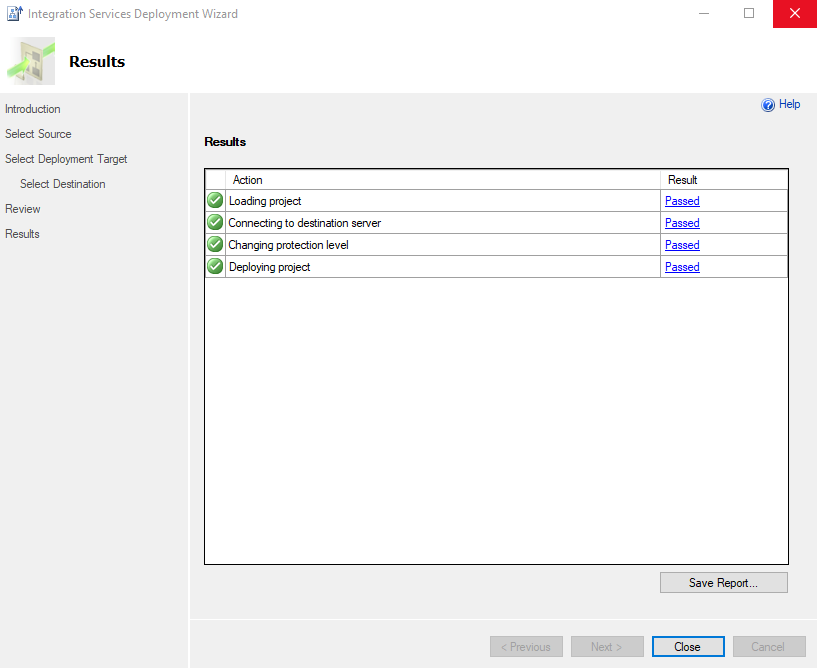
The project is deployed and ready to be ran:
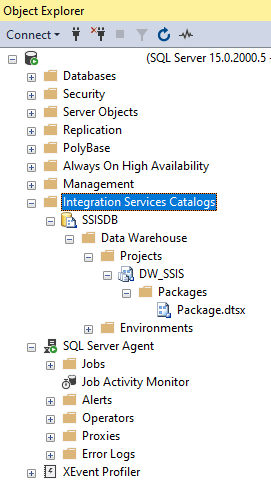
SQL Server Task Agent
Automate the package to run on a timed schedule with SQL Server Task Agent:
